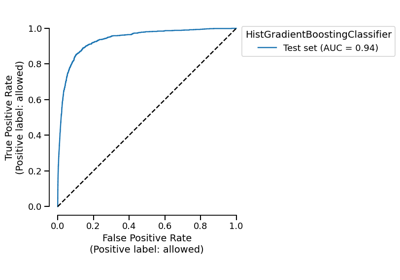
train_test_split#
- skore.train_test_split(*arrays, X=None, y=None, test_size=None, train_size=None, random_state=None, shuffle=True, stratify=None, as_dict=False, **keyword_arrays)[source]#
Perform train-test-split of data.
This is a wrapper over scikit-learn’s
sklearn.model_selection.train_test_split()helper function, enriching it with various warnings.The signature is fully compatible with sklearn’s
train_test_split, and some keyword arguments are added to make the detection of issues more accurate. For instance, argumentyhas been added to pass the target explicitly, which makes it easier to detect issues with the target.See the train_test_split: get diagnostics when splitting your data example.
- Parameters:
- *arrayssequence of indexables with same length / shape[0]
Allowed inputs are lists, numpy arrays, scipy-sparse matrices or pandas dataframes.
- Xarray-like, optional
If not None, will be appended to the list of arrays passed positionally.
- yarray-like, optional
If not None, will be appended to the list of arrays passed positionally, after
X. If None, it is assumed that the last array inarraysisy.- test_sizefloat or int, optional
If float, should be between 0.0 and 1.0 and represent the proportion of the dataset to include in the test split. If int, represents the absolute number of test samples. If None, the value is set to the complement of the train size. If train_size is also None, it will be set to 0.25.
- train_sizefloat or int, optional
If float, should be between 0.0 and 1.0 and represent the proportion of the dataset to include in the train split. If int, represents the absolute number of train samples. If None, the value is automatically set to the complement of the test size.
- random_stateint or numpy RandomState instance, optional
Controls the shuffling applied to the data before applying the split. Pass an int for reproducible output across multiple function calls.
- shufflebool, default is True
Whether or not to shuffle the data before splitting. If shuffle=False then stratify must be None.
- stratifyarray-like, optional
If not None, data is split in a stratified fashion, using this as the class labels.
- as_dictbool, default is False
If True, returns a Dictionary with keys values
X_train,X_test,y_train, andy_testinstead of a List. Requires data to be passed as keyword arguments, though the first two positional arguments are implicitly treated as X and y.- **keyword_arraysarray-like, optional
Additional array-like arguments passed by keyword. Used to determine the keys of the output dict when
as_dict=True.
- Returns:
- splittinglist or dict
If
as_dict=False(the default): List containing train-test split of inputs. The length of the list is twice the number of arrays passed, including theXandykeyword arguments. If arrays are passed positionally as well as throughXandy, the output arrays are ordered as follows: first the arrays passed positionally, in the order they were passed, thenXif it was passed, thenyif it was passed.If
as_dict=True: Dictionary with keysX_train,X_test,y_train, andy_test, each containing respective split data.
Examples
>>> # xdoctest: +SKIP >>> import numpy as np >>> X, y = np.arange(10).reshape((5, 2)), range(5)
>>> # Drop-in replacement for sklearn train_test_split >>> from skore import train_test_split >>> X_train, X_test, y_train, y_test = train_test_split(X, y, ... test_size=0.33, random_state=42) >>> X_train array([[4, 5], [0, 1], [6, 7]])
>>> # Explicit X and y, makes detection of problems easier >>> X_train, X_test, y_train, y_test = train_test_split(X=X, y=y, ... test_size=0.33, random_state=42) >>> X_train array([[4, 5], [0, 1], [6, 7]])
>>> # When passing X and y explicitly, X is returned before y >>> arr = np.arange(10).reshape((5, 2)) >>> splits = train_test_split( ... arr, y=y, X=X, test_size=0.33, random_state=42) >>> arr_train, arr_test, X_train, X_test, y_train, y_test = splits >>> X_train array([[4, 5], [0, 1], [6, 7]])
>>> # Returns dictionary when as_dict is True, inputs must be keyword arguments. >>> sample_weights = np.arange(10).reshape((5, 2)) >>> split_dict = train_test_split( ... X=X, y=y, sample_weights=sample_weights, as_dict=True, random_state=0) >>> split_dict {'X_train': ..., 'X_test': ..., 'y_train': ..., 'y_test': ..., 'sample_weights_train': ..., 'sample_weights_test': ...}
>>> # With as_dict is True, the first 2 arguments are implicitly treated as X and y >>> train_test_split(X, as_dict=True) {'X_train': ..., 'X_test': ...} >>> train_test_split(X, y, as_dict=True) {'X_train': ..., 'X_test': ..., 'y_train': ..., 'y_test': ...} >>> train_test_split(X, y, sample_weights=sample_weights, as_dict=True) {'X_train': ..., 'X_test': ..., 'y_train': ..., 'y_test': ..., 'sample_weights_train': ..., 'sample_weights_test': ...}
Gallery examples#
EstimatorReport: Get insights from any scikit-learn estimator

train_test_split: get diagnostics when splitting your data