Note
Go to the end to download the full example code.
Simplified and structured experiment reporting#
This example shows how to leverage skore for structuring useful experiment information
allowing to get insights from machine learning experiments.
Loading a non-trivial dataset#
We use a skrub dataset that contains information about employees and their salaries. We will see that this dataset is non-trivial.
from skrub.datasets import fetch_employee_salaries
datasets = fetch_employee_salaries()
df, y = datasets.X, datasets.y
Downloading 'employee_salaries' from https://github.com/skrub-data/skrub-data-files/raw/refs/heads/main/employee_salaries.zip (attempt 1/3)
Let’s first have a condensed summary of the input data using a
skrub.TableReport.
from skrub import TableReport
TableReport(df)
| gender | department | department_name | division | assignment_category | employee_position_title | date_first_hired | year_first_hired | |
|---|---|---|---|---|---|---|---|---|
| 0 | F | POL | Department of Police | MSB Information Mgmt and Tech Division Records Management Section | Fulltime-Regular | Office Services Coordinator | 09/22/1986 | 1,986 |
| 1 | M | POL | Department of Police | ISB Major Crimes Division Fugitive Section | Fulltime-Regular | Master Police Officer | 09/12/1988 | 1,988 |
| 2 | F | HHS | Department of Health and Human Services | Adult Protective and Case Management Services | Fulltime-Regular | Social Worker IV | 11/19/1989 | 1,989 |
| 3 | M | COR | Correction and Rehabilitation | PRRS Facility and Security | Fulltime-Regular | Resident Supervisor II | 05/05/2014 | 2,014 |
| 4 | M | HCA | Department of Housing and Community Affairs | Affordable Housing Programs | Fulltime-Regular | Planning Specialist III | 03/05/2007 | 2,007 |
| 9,223 | F | HHS | Department of Health and Human Services | School Based Health Centers | Fulltime-Regular | Community Health Nurse II | 11/03/2015 | 2,015 |
| 9,224 | F | FRS | Fire and Rescue Services | Human Resources Division | Fulltime-Regular | Fire/Rescue Division Chief | 11/28/1988 | 1,988 |
| 9,225 | M | HHS | Department of Health and Human Services | Child and Adolescent Mental Health Clinic Services | Parttime-Regular | Medical Doctor IV - Psychiatrist | 04/30/2001 | 2,001 |
| 9,226 | M | CCL | County Council | Council Central Staff | Fulltime-Regular | Manager II | 09/05/2006 | 2,006 |
| 9,227 | M | DLC | Department of Liquor Control | Licensure, Regulation and Education | Fulltime-Regular | Alcohol/Tobacco Enforcement Specialist II | 01/30/2012 | 2,012 |
gender
ObjectDType- Null values
- 17 (0.2%)
- Unique values
- 2 (< 0.1%)
Most frequent values
department
ObjectDType- Null values
- 0 (0.0%)
- Unique values
- 37 (0.4%)
Most frequent values
department_name
ObjectDType- Null values
- 0 (0.0%)
- Unique values
- 37 (0.4%)
Most frequent values
division
ObjectDType- Null values
- 0 (0.0%)
- Unique values
-
694 (7.5%)
This column has a high cardinality (> 40).
Most frequent values
assignment_category
ObjectDType- Null values
- 0 (0.0%)
- Unique values
- 2 (< 0.1%)
Most frequent values
employee_position_title
ObjectDType- Null values
- 0 (0.0%)
- Unique values
-
443 (4.8%)
This column has a high cardinality (> 40).
Most frequent values
date_first_hired
ObjectDType- Null values
- 0 (0.0%)
- Unique values
-
2,264 (24.5%)
This column has a high cardinality (> 40).
Most frequent values
year_first_hired
Int64DType- Null values
- 0 (0.0%)
- Unique values
-
51 (0.6%)
This column has a high cardinality (> 40).
- Mean ± Std
- 2.00e+03 ± 9.33
- Median ± IQR
- 2,005 ± 14
- Min | Max
- 1,965 | 2,016
No columns match the selected filter: . You can change the column filter in the dropdown menu above.
| Column | Column name | dtype | Is sorted | Null values | Unique values | Mean | Std | Min | Median | Max |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | gender | ObjectDType | False | 17 (0.2%) | 2 (< 0.1%) | |||||
| 1 | department | ObjectDType | False | 0 (0.0%) | 37 (0.4%) | |||||
| 2 | department_name | ObjectDType | False | 0 (0.0%) | 37 (0.4%) | |||||
| 3 | division | ObjectDType | False | 0 (0.0%) | 694 (7.5%) | |||||
| 4 | assignment_category | ObjectDType | False | 0 (0.0%) | 2 (< 0.1%) | |||||
| 5 | employee_position_title | ObjectDType | False | 0 (0.0%) | 443 (4.8%) | |||||
| 6 | date_first_hired | ObjectDType | False | 0 (0.0%) | 2264 (24.5%) | |||||
| 7 | year_first_hired | Int64DType | False | 0 (0.0%) | 51 (0.6%) | 2.00e+03 | 9.33 | 1,965 | 2,005 | 2,016 |
No columns match the selected filter: . You can change the column filter in the dropdown menu above.
gender
ObjectDType- Null values
- 17 (0.2%)
- Unique values
- 2 (< 0.1%)
Most frequent values
department
ObjectDType- Null values
- 0 (0.0%)
- Unique values
- 37 (0.4%)
Most frequent values
department_name
ObjectDType- Null values
- 0 (0.0%)
- Unique values
- 37 (0.4%)
Most frequent values
division
ObjectDType- Null values
- 0 (0.0%)
- Unique values
-
694 (7.5%)
This column has a high cardinality (> 40).
Most frequent values
assignment_category
ObjectDType- Null values
- 0 (0.0%)
- Unique values
- 2 (< 0.1%)
Most frequent values
employee_position_title
ObjectDType- Null values
- 0 (0.0%)
- Unique values
-
443 (4.8%)
This column has a high cardinality (> 40).
Most frequent values
date_first_hired
ObjectDType- Null values
- 0 (0.0%)
- Unique values
-
2,264 (24.5%)
This column has a high cardinality (> 40).
Most frequent values
year_first_hired
Int64DType- Null values
- 0 (0.0%)
- Unique values
-
51 (0.6%)
This column has a high cardinality (> 40).
- Mean ± Std
- 2.00e+03 ± 9.33
- Median ± IQR
- 2,005 ± 14
- Min | Max
- 1,965 | 2,016
No columns match the selected filter: . You can change the column filter in the dropdown menu above.
| Column 1 | Column 2 | Cramér's V | Pearson's Correlation |
|---|---|---|---|
| department | department_name | 1.00 | |
| division | assignment_category | 0.593 | |
| assignment_category | employee_position_title | 0.497 | |
| department_name | assignment_category | 0.422 | |
| department | assignment_category | 0.422 | |
| department | employee_position_title | 0.413 | |
| department_name | employee_position_title | 0.413 | |
| division | employee_position_title | 0.410 | |
| department | division | 0.381 | |
| department_name | division | 0.381 | |
| gender | department | 0.380 | |
| gender | department_name | 0.380 | |
| gender | assignment_category | 0.294 | |
| gender | employee_position_title | 0.275 | |
| gender | division | 0.265 | |
| employee_position_title | date_first_hired | 0.179 | |
| date_first_hired | year_first_hired | 0.151 | |
| department | date_first_hired | 0.150 | |
| department_name | date_first_hired | 0.150 | |
| employee_position_title | year_first_hired | 0.131 | |
| gender | date_first_hired | 0.104 | |
| division | year_first_hired | 0.0862 | |
| department | year_first_hired | 0.0811 | |
| department_name | year_first_hired | 0.0811 | |
| assignment_category | date_first_hired | 0.0756 | |
| division | date_first_hired | 0.0728 | |
| gender | year_first_hired | 0.0641 | |
| assignment_category | year_first_hired | 0.0519 |
Please enable javascript
The skrub table reports need javascript to display correctly. If you are displaying a report in a Jupyter notebook and you see this message, you may need to re-execute the cell or to trust the notebook (button on the top right or "File > Trust notebook").
From the table report, we can make the following observations:
Looking at the Table tab, we observe that the year related to the
date_first_hiredcolumn is also present in thedatecolumn. Hence, we should beware of not creating twice the same feature during the feature engineering.Looking at the Stats tab:
The type of data is heterogeneous: we mainly have categorical and date-related features.
The
divisionandemployee_position_titlefeatures contain a large number of categories. It is something that we should consider in our feature engineering.
Looking at the Associations tab, we observe that two features are holding the exact same information:
departmentanddepartment_name. Hence, during our feature engineering, we could potentially drop one of them if the final predictive model is sensitive to the collinearity.
In terms of target and thus the task that we want to solve, we are interested in predicting the salary of an employee given the previous features. We therefore have a regression task at end.
| current_annual_salary | |
|---|---|
| 0 | 6.92e+04 |
| 1 | 9.74e+04 |
| 2 | 1.05e+05 |
| 3 | 5.27e+04 |
| 4 | 9.34e+04 |
| 9,223 | 7.21e+04 |
| 9,224 | 1.70e+05 |
| 9,225 | 1.03e+05 |
| 9,226 | 1.54e+05 |
| 9,227 | 7.55e+04 |
current_annual_salary
Float64DType- Null values
- 0 (0.0%)
- Unique values
-
3,403 (36.9%)
This column has a high cardinality (> 40).
- Mean ± Std
- 7.34e+04 ± 2.91e+04
- Median ± IQR
- 6.94e+04 ± 3.94e+04
- Min | Max
- 9.20e+03 | 3.03e+05
No columns match the selected filter: . You can change the column filter in the dropdown menu above.
| Column | Column name | dtype | Is sorted | Null values | Unique values | Mean | Std | Min | Median | Max |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | current_annual_salary | Float64DType | False | 0 (0.0%) | 3403 (36.9%) | 7.34e+04 | 2.91e+04 | 9.20e+03 | 6.94e+04 | 3.03e+05 |
No columns match the selected filter: . You can change the column filter in the dropdown menu above.
current_annual_salary
Float64DType- Null values
- 0 (0.0%)
- Unique values
-
3,403 (36.9%)
This column has a high cardinality (> 40).
- Mean ± Std
- 7.34e+04 ± 2.91e+04
- Median ± IQR
- 6.94e+04 ± 3.94e+04
- Min | Max
- 9.20e+03 | 3.03e+05
No columns match the selected filter: . You can change the column filter in the dropdown menu above.
Please enable javascript
The skrub table reports need javascript to display correctly. If you are displaying a report in a Jupyter notebook and you see this message, you may need to re-execute the cell or to trust the notebook (button on the top right or "File > Trust notebook").
Later in this example, we will show that skore stores similar information when a
model is trained on a dataset, thus enabling us to get quick insights on the dataset
used to train and test the model.
Tree-based model#
Let’s start by creating a tree-based model using some out-of-the-box tools.
For feature engineering, we use skrub’s TableVectorizer.
To deal with the high cardinality of the categorical features, we use a
StringEncoder to encode the categorical features.
Finally, we use a HistGradientBoostingRegressor as a
base estimator, it is a rather robust model.
Modelling#
from sklearn.ensemble import HistGradientBoostingRegressor
from sklearn.pipeline import make_pipeline
from skrub import StringEncoder, TableVectorizer
hgbt_model = make_pipeline(
TableVectorizer(high_cardinality=StringEncoder()),
HistGradientBoostingRegressor(),
)
hgbt_model
Evaluation#
Let us compute the 5-fold cross-validation report for this model using
evaluate() with splitter=5. This will return a
CrossValidationReport object.
from skore import evaluate
hgbt_model_report = evaluate(hgbt_model, df, y, splitter=5, n_jobs=4)
hgbt_model_report.help()
A report provides a collection of useful information. For instance, it allows to compute on demand the predictions of the model and some performance metrics.
Side-note: performance metrics rely on the model predictions, so the report saves the predictions once at the beginning to speed up metric computations.
We can now have a look at the performance of the model with some standard metrics.
hgbt_model_report.metrics.summarize().frame()
Similarly to what we saw in the previous section, the
skore.CrossValidationReport also stores some information about the dataset
used.
data_display = hgbt_model_report.data.summarize()
data_display
| gender | department | department_name | division | assignment_category | employee_position_title | date_first_hired | year_first_hired | current_annual_salary | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | F | POL | Department of Police | MSB Information Mgmt and Tech Division Records Management Section | Fulltime-Regular | Office Services Coordinator | 09/22/1986 | 1,986 | 6.92e+04 |
| 1 | M | POL | Department of Police | ISB Major Crimes Division Fugitive Section | Fulltime-Regular | Master Police Officer | 09/12/1988 | 1,988 | 9.74e+04 |
| 2 | F | HHS | Department of Health and Human Services | Adult Protective and Case Management Services | Fulltime-Regular | Social Worker IV | 11/19/1989 | 1,989 | 1.05e+05 |
| 3 | M | COR | Correction and Rehabilitation | PRRS Facility and Security | Fulltime-Regular | Resident Supervisor II | 05/05/2014 | 2,014 | 5.27e+04 |
| 4 | M | HCA | Department of Housing and Community Affairs | Affordable Housing Programs | Fulltime-Regular | Planning Specialist III | 03/05/2007 | 2,007 | 9.34e+04 |
| 9,223 | F | HHS | Department of Health and Human Services | School Based Health Centers | Fulltime-Regular | Community Health Nurse II | 11/03/2015 | 2,015 | 7.21e+04 |
| 9,224 | F | FRS | Fire and Rescue Services | Human Resources Division | Fulltime-Regular | Fire/Rescue Division Chief | 11/28/1988 | 1,988 | 1.70e+05 |
| 9,225 | M | HHS | Department of Health and Human Services | Child and Adolescent Mental Health Clinic Services | Parttime-Regular | Medical Doctor IV - Psychiatrist | 04/30/2001 | 2,001 | 1.03e+05 |
| 9,226 | M | CCL | County Council | Council Central Staff | Fulltime-Regular | Manager II | 09/05/2006 | 2,006 | 1.54e+05 |
| 9,227 | M | DLC | Department of Liquor Control | Licensure, Regulation and Education | Fulltime-Regular | Alcohol/Tobacco Enforcement Specialist II | 01/30/2012 | 2,012 | 7.55e+04 |
gender
ObjectDType- Null values
- 17 (0.2%)
- Unique values
- 2 (< 0.1%)
Most frequent values
department
ObjectDType- Null values
- 0 (0.0%)
- Unique values
- 37 (0.4%)
Most frequent values
department_name
ObjectDType- Null values
- 0 (0.0%)
- Unique values
- 37 (0.4%)
Most frequent values
division
ObjectDType- Null values
- 0 (0.0%)
- Unique values
-
694 (7.5%)
This column has a high cardinality (> 40).
Most frequent values
assignment_category
ObjectDType- Null values
- 0 (0.0%)
- Unique values
- 2 (< 0.1%)
Most frequent values
employee_position_title
ObjectDType- Null values
- 0 (0.0%)
- Unique values
-
443 (4.8%)
This column has a high cardinality (> 40).
Most frequent values
date_first_hired
ObjectDType- Null values
- 0 (0.0%)
- Unique values
-
2,264 (24.5%)
This column has a high cardinality (> 40).
Most frequent values
year_first_hired
Int64DType- Null values
- 0 (0.0%)
- Unique values
-
51 (0.6%)
This column has a high cardinality (> 40).
- Mean ± Std
- 2.00e+03 ± 9.33
- Median ± IQR
- 2,005 ± 14
- Min | Max
- 1,965 | 2,016
current_annual_salary
Float64DType- Null values
- 0 (0.0%)
- Unique values
-
3,403 (36.9%)
This column has a high cardinality (> 40).
- Mean ± Std
- 7.34e+04 ± 2.91e+04
- Median ± IQR
- 6.94e+04 ± 3.94e+04
- Min | Max
- 9.20e+03 | 3.03e+05
No columns match the selected filter: . You can change the column filter in the dropdown menu above.
| Column | Column name | dtype | Is sorted | Null values | Unique values | Mean | Std | Min | Median | Max |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | gender | ObjectDType | False | 17 (0.2%) | 2 (< 0.1%) | |||||
| 1 | department | ObjectDType | False | 0 (0.0%) | 37 (0.4%) | |||||
| 2 | department_name | ObjectDType | False | 0 (0.0%) | 37 (0.4%) | |||||
| 3 | division | ObjectDType | False | 0 (0.0%) | 694 (7.5%) | |||||
| 4 | assignment_category | ObjectDType | False | 0 (0.0%) | 2 (< 0.1%) | |||||
| 5 | employee_position_title | ObjectDType | False | 0 (0.0%) | 443 (4.8%) | |||||
| 6 | date_first_hired | ObjectDType | False | 0 (0.0%) | 2264 (24.5%) | |||||
| 7 | year_first_hired | Int64DType | False | 0 (0.0%) | 51 (0.6%) | 2.00e+03 | 9.33 | 1,965 | 2,005 | 2,016 |
| 8 | current_annual_salary | Float64DType | False | 0 (0.0%) | 3403 (36.9%) | 7.34e+04 | 2.91e+04 | 9.20e+03 | 6.94e+04 | 3.03e+05 |
No columns match the selected filter: . You can change the column filter in the dropdown menu above.
gender
ObjectDType- Null values
- 17 (0.2%)
- Unique values
- 2 (< 0.1%)
Most frequent values
department
ObjectDType- Null values
- 0 (0.0%)
- Unique values
- 37 (0.4%)
Most frequent values
department_name
ObjectDType- Null values
- 0 (0.0%)
- Unique values
- 37 (0.4%)
Most frequent values
division
ObjectDType- Null values
- 0 (0.0%)
- Unique values
-
694 (7.5%)
This column has a high cardinality (> 40).
Most frequent values
assignment_category
ObjectDType- Null values
- 0 (0.0%)
- Unique values
- 2 (< 0.1%)
Most frequent values
employee_position_title
ObjectDType- Null values
- 0 (0.0%)
- Unique values
-
443 (4.8%)
This column has a high cardinality (> 40).
Most frequent values
date_first_hired
ObjectDType- Null values
- 0 (0.0%)
- Unique values
-
2,264 (24.5%)
This column has a high cardinality (> 40).
Most frequent values
year_first_hired
Int64DType- Null values
- 0 (0.0%)
- Unique values
-
51 (0.6%)
This column has a high cardinality (> 40).
- Mean ± Std
- 2.00e+03 ± 9.33
- Median ± IQR
- 2,005 ± 14
- Min | Max
- 1,965 | 2,016
current_annual_salary
Float64DType- Null values
- 0 (0.0%)
- Unique values
-
3,403 (36.9%)
This column has a high cardinality (> 40).
- Mean ± Std
- 7.34e+04 ± 2.91e+04
- Median ± IQR
- 6.94e+04 ± 3.94e+04
- Min | Max
- 9.20e+03 | 3.03e+05
No columns match the selected filter: . You can change the column filter in the dropdown menu above.
| Column 1 | Column 2 | Cramér's V | Pearson's Correlation |
|---|---|---|---|
| department | department_name | 1.00 | |
| assignment_category | current_annual_salary | 0.698 | |
| division | assignment_category | 0.593 | |
| assignment_category | employee_position_title | 0.497 | |
| department | assignment_category | 0.422 | |
| department_name | assignment_category | 0.422 | |
| department | employee_position_title | 0.413 | |
| department_name | employee_position_title | 0.413 | |
| division | employee_position_title | 0.410 | |
| department_name | division | 0.381 | |
| department | division | 0.381 | |
| gender | department | 0.380 | |
| gender | department_name | 0.380 | |
| gender | assignment_category | 0.294 | |
| employee_position_title | current_annual_salary | 0.292 | |
| gender | employee_position_title | 0.275 | |
| gender | division | 0.265 | |
| division | current_annual_salary | 0.221 | |
| year_first_hired | current_annual_salary | 0.218 | -0.480 |
| department_name | current_annual_salary | 0.207 | |
| department | current_annual_salary | 0.207 | |
| employee_position_title | date_first_hired | 0.179 | |
| date_first_hired | year_first_hired | 0.151 | |
| department | date_first_hired | 0.150 | |
| department_name | date_first_hired | 0.150 | |
| employee_position_title | year_first_hired | 0.131 | |
| gender | current_annual_salary | 0.123 | |
| date_first_hired | current_annual_salary | 0.113 | |
| gender | date_first_hired | 0.104 | |
| division | year_first_hired | 0.0862 | |
| department | year_first_hired | 0.0811 | |
| department_name | year_first_hired | 0.0811 | |
| assignment_category | date_first_hired | 0.0756 | |
| division | date_first_hired | 0.0728 | |
| gender | year_first_hired | 0.0641 | |
| assignment_category | year_first_hired | 0.0519 |
Please enable javascript
The skrub table reports need javascript to display correctly. If you are displaying a report in a Jupyter notebook and you see this message, you may need to re-execute the cell or to trust the notebook (button on the top right or "File > Trust notebook").
The display obtained allows for a quick overview with the same HTML-based view
as the skrub.TableReport we have seen earlier. In addition, you can access
a skore.TableReportDisplay.plot() method to have a particular focus on one
potential analysis. For instance, we can get a figure representing the correlation
matrix of the dataset.
fig = data_display.plot(kind="corr")
fig.set_size_inches(10, 10)
fig
<Figure size 1000x1000 with 2 Axes>
We get the results from some statistical metrics aggregated over the cross-validation splits as well as some performance metrics related to the time it took to train and test the model.
The skore.CrossValidationReport also provides a way to inspect similar
information at the level of each cross-validation split by accessing an
skore.EstimatorReport for each split.
hgbt_split_1 = hgbt_model_report.reports_[0]
hgbt_split_1.metrics.summarize().frame(favorability=True)
The favorability of each metric indicates whether the metric is better when higher or lower.
Linear model#
Now that we have established a first model that serves as a baseline, we shall proceed to define a quite complex linear model: a pipeline with a complex feature engineering that uses a linear model as the base estimator.
Modelling#
import numpy as np
from sklearn.compose import make_column_transformer
from sklearn.linear_model import RidgeCV
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import OneHotEncoder, SplineTransformer
from skrub import DatetimeEncoder, DropCols, GapEncoder, ToDatetime
def periodic_spline_transformer(period, n_splines=None, degree=3):
if n_splines is None:
n_splines = period
n_knots = n_splines + 1 # periodic and include_bias is True
return SplineTransformer(
degree=degree,
n_knots=n_knots,
knots=np.linspace(0, period, n_knots).reshape(n_knots, 1),
extrapolation="periodic",
include_bias=True,
)
one_hot_features = ["gender", "department_name", "assignment_category"]
datetime_features = "date_first_hired"
date_encoder = make_pipeline(
ToDatetime(),
DatetimeEncoder(resolution="day", add_weekday=True, add_total_seconds=False),
DropCols("date_first_hired_year"),
)
date_engineering = make_column_transformer(
(periodic_spline_transformer(12, n_splines=6), ["date_first_hired_month"]),
(periodic_spline_transformer(31, n_splines=15), ["date_first_hired_day"]),
(periodic_spline_transformer(7, n_splines=3), ["date_first_hired_weekday"]),
)
feature_engineering_date = make_pipeline(date_encoder, date_engineering)
preprocessing = make_column_transformer(
(feature_engineering_date, datetime_features),
(OneHotEncoder(drop="if_binary", handle_unknown="ignore"), one_hot_features),
(GapEncoder(n_components=100), "division"),
(GapEncoder(n_components=100), "employee_position_title"),
)
linear_model = make_pipeline(preprocessing, RidgeCV(alphas=np.logspace(-3, 3, 100)))
linear_model
In the diagram above, we can see what how we performed our feature engineering:
For categorical features, we use two approaches. If the number of categories is relatively small, we use a
OneHotEncoder. If the number of categories is large, we use aGapEncoderthat is designed to deal with high cardinality categorical features.Then, we have another transformation to encode the date features. We first split the date into multiple features (day, month, and year). Then, we apply a periodic spline transformation to each of the date features in order to capture the periodicity of the data.
Finally, we fit a
RidgeCVmodel.
Evaluation#
Now, we want to evaluate this linear model via cross-validation (with 5 folds).
For that, we use again evaluate() with splitter=5.
linear_model_report = evaluate(linear_model, df, y, splitter=5, n_jobs=4)
linear_model_report.help()
We observe that the cross-validation report has detected that we have a regression task at hand and thus provides us with some metrics and plots that make sense with regards to our specific problem at hand.
We can now have a look at the performance of the model with some standard metrics.
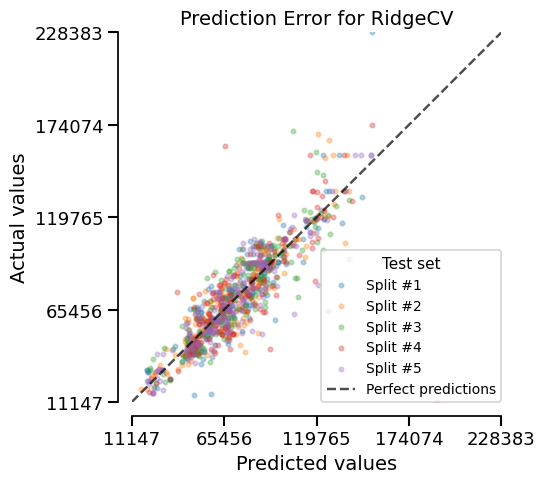
linear_model_report.metrics.summarize().frame(favorability=True)
Comparing the models#
Now that we cross-validated our models, we can make some further comparison using
the compare() function that returns a ComparisonReport:
from skore import compare
comparator = compare([hgbt_model_report, linear_model_report])
comparator.metrics.summarize().frame(favorability=True)
In addition, if we forgot to compute a specific metric
(e.g. mean_absolute_error()),
we can easily add it to the report, without re-training the model and even
without re-computing the predictions since they are cached internally in the report.
This allows us to save some potentially huge computation time.
comparator.metrics.add(metric="neg_mean_absolute_error", name="MAE")
comparator.metrics.summarize().frame()
Finally, we can even get a deeper understanding by analyzing each split in the
CrossValidationReport.
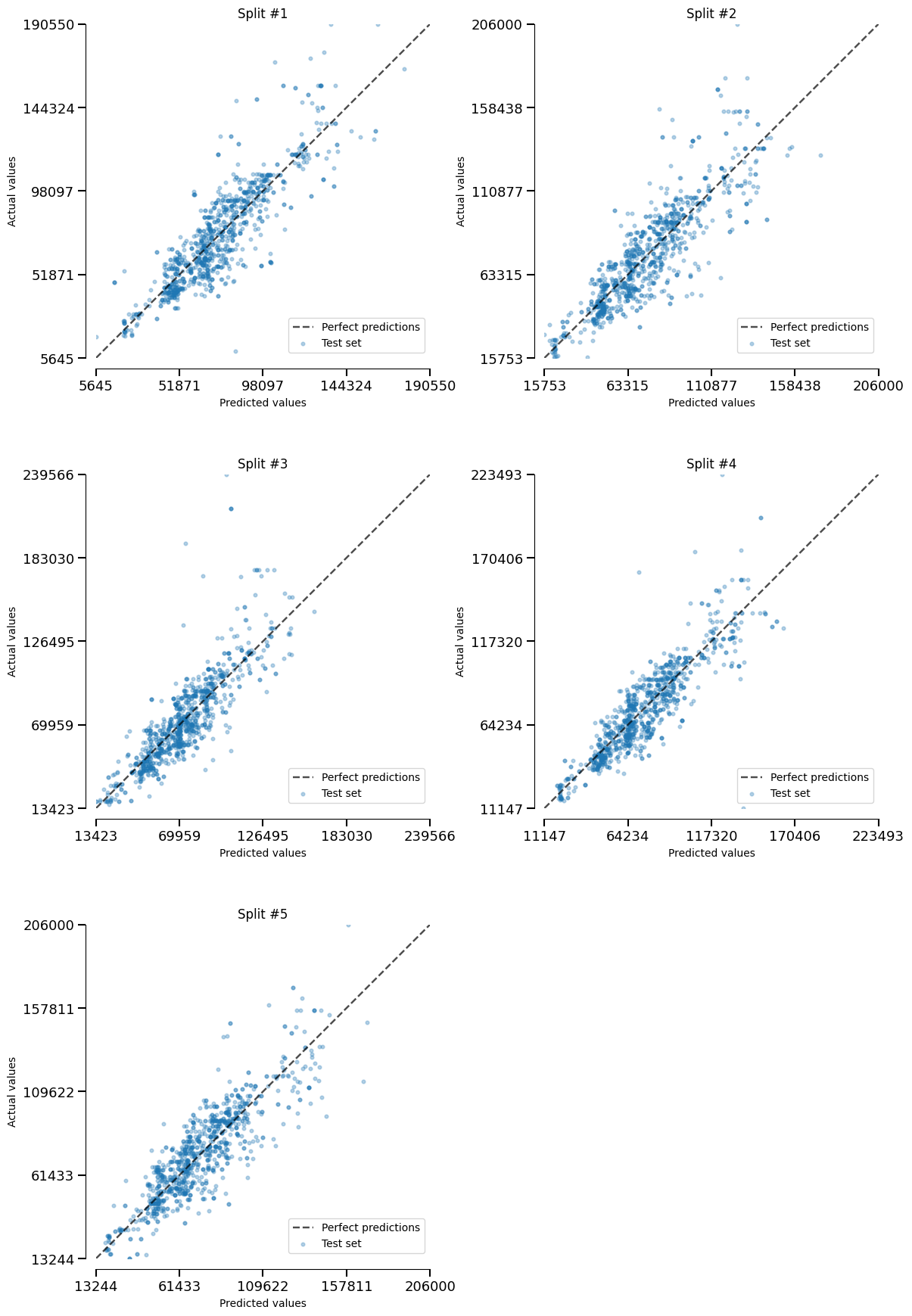
Here, we plot the actual-vs-predicted values for each split.
_ = linear_model_report.metrics.prediction_error().plot(kind="actual_vs_predicted")
Conclusion#
This example showcased skore’s integrated approach to machine learning workflow,
from initial data exploration with TableReport through model development and
evaluation with CrossValidationReport.
We demonstrated how skore automatically captures dataset information and provides
efficient caching, enabling quick insights and flexible model comparison.
The workflow highlights skore’s ability to streamline the entire ML process while
maintaining computational efficiency.
Total running time of the script: (1 minutes 13.206 seconds)