ComparisonReport#
- class skore.ComparisonReport(reports, *, n_jobs=None)[source]#
Compare several estimator or cross-validation reports.
Refer to the Comparison report section of the user guide for more details.
- Parameters:
- reportslist of reports or dict
Reports to compare. If a dict, keys will be used to label the estimators; if a list, the labels are computed from the estimator class names. Expects at least two reports to compare, with the same test target.
- n_jobsint, default=None
Number of jobs to run in parallel. Training the estimators and computing the scores are parallelized. When accessing some methods of the
ComparisonReport, then_jobsparameter is used to parallelize the computation.Nonemeans 1 unless in ajoblib.parallel_backendcontext.-1means using all processors.
- Attributes:
- reports_dict mapping names to reports
The compared reports.
metricsMetricsAccessorAccessor for metrics-related operations.
inspectionInspectionAccessorAccessor for model inspection related operations.
checksChecksAccessorAccessor for checks-related operations.
See also
skore.EstimatorReportReport for a fitted estimator.
skore.CrossValidationReportReport for the cross-validation of an estimator.
Notes
Reports passed to
ComparisonReportare not copied. If you pass a report toComparisonReport, and then modify the report outside later, it will affect the report stored inside theComparisonReportas well, which can lead to inconsistent results. For this reason, modifying reports after creation is strongly discouraged.Examples
>>> from sklearn.datasets import make_classification >>> from sklearn.model_selection import train_test_split >>> from sklearn.linear_model import LogisticRegression >>> from skore import ComparisonReport, EstimatorReport >>> X, y = make_classification(random_state=42) >>> X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42) >>> estimator_1 = LogisticRegression() >>> estimator_report_1 = EstimatorReport( ... estimator_1, X_train=X_train, y_train=y_train, X_test=X_test, y_test=y_test ... ) >>> estimator_2 = LogisticRegression(C=2) # Different regularization >>> estimator_report_2 = EstimatorReport( ... estimator_2, X_train=X_train, y_train=y_train, X_test=X_test, y_test=y_test ... ) >>> report = ComparisonReport([estimator_report_1, estimator_report_2]) >>> report.reports_ {'LogisticRegression_1': ..., 'LogisticRegression_2': ...} >>> report = ComparisonReport( ... {"model1": estimator_report_1, "model2": estimator_report_2} ... ) >>> report.reports_ {'model1': ..., 'model2': ...}
>>> from sklearn.datasets import make_classification >>> from sklearn.linear_model import LogisticRegression >>> from skore import ComparisonReport, CrossValidationReport >>> X, y = make_classification(random_state=42) >>> estimator_1 = LogisticRegression() >>> estimator_2 = LogisticRegression(C=2) # Different regularization >>> report_1 = CrossValidationReport(estimator_1, X, y) >>> report_2 = CrossValidationReport(estimator_2, X, y) >>> report = ComparisonReport([report_1, report_2]) >>> report = ComparisonReport({"model1": report_1, "model2": report_2})
- cache_predictions()[source]#
Cache the predictions for sub-estimators reports.
Examples
>>> from sklearn.datasets import make_classification >>> from sklearn.linear_model import LogisticRegression >>> from skore import compare, evaluate >>> X, y = make_classification(random_state=42) >>> estimator_1 = LogisticRegression() >>> estimator_report_1 = evaluate(estimator_1, X, y, splitter=0.2) >>> estimator_2 = LogisticRegression(C=2) # Different regularization >>> estimator_report_2 = evaluate(estimator_2, X, y, splitter=0.2) >>> report = compare([estimator_report_1, estimator_report_2]) >>> report.cache_predictions()
- clear_cache()[source]#
Clear the cache.
Examples
>>> from sklearn.datasets import make_classification >>> from sklearn.linear_model import LogisticRegression >>> from skore import compare, evaluate >>> X, y = make_classification(random_state=42) >>> estimator_1 = LogisticRegression() >>> estimator_report_1 = evaluate(estimator_1, X, y, splitter=0.2) >>> estimator_2 = LogisticRegression(C=2) # Different regularization >>> estimator_report_2 = evaluate(estimator_2, X, y, splitter=0.2) >>> report = compare([estimator_report_1, estimator_report_2]) >>> report.cache_predictions() >>> report.clear_cache()
- create_estimator_report(*, report_key, X_test=None, y_test=None, test_data=None, concatenate_train_and_test=False)[source]#
Create an estimator report from one of the reports in the comparison.
This method creates a new
EstimatorReportwith the same estimator and the same data as the chosen report. It is useful to evaluate and deploy a model that was deemed optimal during the comparison. Provide a held out test set to properly evaluate the performance of the model.- Parameters:
- report_keystr
The key associated with the estimator to create a report for, as stored in the
reports_attribute of theComparisonReport. List the available keys withreports_.keys().- X_test{array-like, sparse matrix} of shape (n_samples, n_features) or None
Testing data when the chosen report uses tabular scikit-learn
X/y. Must be provided together withy_testunless onlytest_datais used for a skrub-backed report.- y_testarray-like of shape (n_samples,) or (n_samples, n_outputs) or None
Testing target for tabular scikit-learn data.
- test_datadict or None
When the chosen report is skrub-backed, bindings for variables contained in the DataOp (e.g.
{"X": X_df, ...}) for the held-out evaluation set. Required in that case;X_testandy_testmust then be omitted.- concatenate_train_and_testbool, default=False
When the chosen entry is an
EstimatorReportbacked by tabular scikit-learn data, controls whether to concatenate that report’s train and test splits into a single training set before fitting on the held-outX_test/y_testyou provide. IfFalse(default), the new report is fit on the report’s originalX_train.This option must be
Falseifreport_keyrefers to aCrossValidationReportorthe estimator is a skrub
SkrubLearnerorthe estimator was built from a skrub
DataOp.
- Returns:
EstimatorReportThe estimator report.
Examples
>>> from sklearn.datasets import make_classification >>> from sklearn.ensemble import RandomForestClassifier >>> from sklearn.linear_model import LogisticRegression >>> from sklearn.model_selection import train_test_split >>> from skore import compare, evaluate >>> X, y = make_classification(random_state=42) >>> X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42) >>> linear_report = evaluate( ... LogisticRegression(random_state=42), X_train, y_train, splitter=5 ... ) >>> forest_report = evaluate( ... RandomForestClassifier(random_state=42), X_train, y_train, splitter=5 ... ) >>> comparison_report = compare([linear_report, forest_report]) >>> summary = comparison_report.metrics.summarize().frame() >>> final_report = comparison_report.create_estimator_report( ... report_key="RandomForestClassifier", X_test=X_test, y_test=y_test ... ) >>> final_report.metrics.summarize().frame()
- get_predictions(*, data_source, response_method='predict')[source]#
Get predictions from the underlying reports.
This method has the advantage to reload from the cache if the predictions were already computed in a previous call.
- Parameters:
- data_source{“test”, “train”}
The data source to use.
“test” : use the test set provided when creating the report.
“train” : use the train set provided when creating the report.
- response_method{“predict”, “predict_proba”, “decision_function”}, default=”predict”
The response method to use to get the predictions.
- Returns:
- list of np.ndarray of shape (n_samples,) or (n_samples, n_classes) or list of such lists
The predictions for each
EstimatorReportorCrossValidationReport.
- Raises:
- ValueError
If the data source is invalid.
Examples
>>> from sklearn.datasets import make_classification >>> from sklearn.linear_model import LogisticRegression >>> from skore import compare, evaluate >>> X, y = make_classification(random_state=42) >>> estimator_1 = LogisticRegression() >>> estimator_report_1 = evaluate(estimator_1, X, y, splitter=0.2) >>> estimator_2 = LogisticRegression(C=2) # Different regularization >>> estimator_report_2 = evaluate(estimator_2, X, y, splitter=0.2) >>> report = compare([estimator_report_1, estimator_report_2]) >>> report.cache_predictions() >>> predictions = report.get_predictions(data_source="test") >>> print([split_predictions.shape for split_predictions in predictions]) [(20,), (20,)]
- to_markdown()[source]#
Return a markdown summary of the report.
The summary contains four sections (Estimators, Metrics, Checks, Data) that mirror the tabs of the HTML representation. Metrics and Checks sections end with a pointer to the corresponding accessor for full details.
- Returns:
- str
The markdown summary of the report.
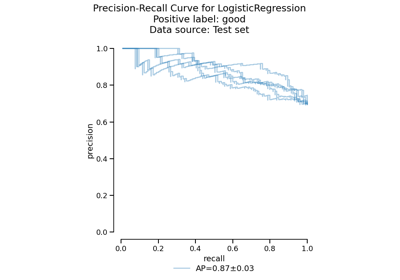
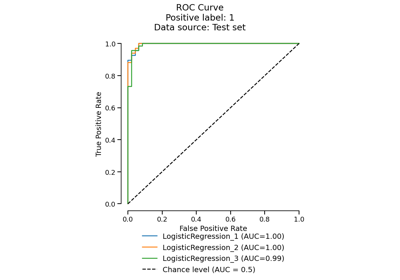
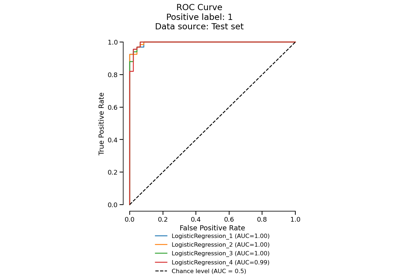
Gallery examples#


EstimatorReport: Inspecting your models with the feature importance