ComparisonReport#
- class skore.ComparisonReport(reports, *, n_jobs=None)[source]#
Report for comparing reports.
This object can be used to compare several :class:`skore.EstimatorReport`s, or several :class:`~skore.CrossValidationReport`s.
Caution
Reports passed to
ComparisonReportare not copied. If you pass a report toComparisonReport, and then modify the report outside later, it will affect the report stored inside theComparisonReportas well, which can lead to inconsistent results. For this reason, modifying reports after creation is strongly discouraged.- Parameters:
- reportslist of reports or dict
Reports to compare. If a dict, keys will be used to label the estimators; if a list, the labels are computed from the estimator class names.
- n_jobsint, default=None
Number of jobs to run in parallel. Training the estimators and computing the scores are parallelized. When accessing some methods of the
ComparisonReport, then_jobsparameter is used to parallelize the computation.Nonemeans 1 unless in ajoblib.parallel_backendcontext.-1means using all processors.
- Attributes:
- reports_list of
EstimatorReportor list of The compared reports.
- report_names_list of str
The names of the compared estimators. If the names are not customized (i.e. the class names are used), a de-duplication process is used to make sure that the names are distinct.
- reports_list of
See also
skore.EstimatorReportReport for a fitted estimator.
skore.CrossValidationReportReport for the cross-validation of an estimator.
Examples
>>> from sklearn.datasets import make_classification >>> from sklearn.model_selection import train_test_split >>> from sklearn.linear_model import LogisticRegression >>> from skore import ComparisonReport, EstimatorReport >>> X, y = make_classification(random_state=42) >>> X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42) >>> estimator_1 = LogisticRegression() >>> estimator_report_1 = EstimatorReport( ... estimator_1, ... X_train=X_train, ... y_train=y_train, ... X_test=X_test, ... y_test=y_test ... ) >>> estimator_2 = LogisticRegression(C=2) # Different regularization >>> estimator_report_2 = EstimatorReport( ... estimator_2, ... X_train=X_train, ... y_train=y_train, ... X_test=X_test, ... y_test=y_test ... ) >>> report = ComparisonReport([estimator_report_1, estimator_report_2]) >>> report.report_names_ ['LogisticRegression_1', 'LogisticRegression_2'] >>> report = ComparisonReport( ... {"model1": estimator_report_1, "model2": estimator_report_2} ... ) >>> report.report_names_ ['model1', 'model2']
>>> from sklearn.datasets import make_classification >>> from sklearn.linear_model import LogisticRegression >>> from skore import ComparisonReport, CrossValidationReport >>> X, y = make_classification(random_state=42) >>> estimator_1 = LogisticRegression() >>> estimator_2 = LogisticRegression(C=2) # Different regularization >>> report_1 = CrossValidationReport(estimator_1, X, y) >>> report_2 = CrossValidationReport(estimator_2, X, y) >>> report = ComparisonReport([report_1, report_2]) >>> report = ComparisonReport({"model1": report_1, "model2": report_2})
- cache_predictions(response_methods='auto', n_jobs=None)[source]#
Cache the predictions for sub-estimators reports.
- Parameters:
- response_methods{“auto”, “predict”, “predict_proba”, “decision_function”}, default=”auto
The methods to use to compute the predictions.
- n_jobsint, default=None
The number of jobs to run in parallel. If
None, we use then_jobsparameter when initializing the report.
Examples
>>> from sklearn.datasets import make_classification >>> from sklearn.linear_model import LogisticRegression >>> from sklearn.model_selection import train_test_split >>> from skore import ComparisonReport, EstimatorReport >>> X, y = make_classification(random_state=42) >>> X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42) >>> estimator_1 = LogisticRegression() >>> estimator_report_1 = EstimatorReport( ... estimator_1, ... X_train=X_train, ... y_train=y_train, ... X_test=X_test, ... y_test=y_test ... ) >>> estimator_2 = LogisticRegression(C=2) # Different regularization >>> estimator_report_2 = EstimatorReport( ... estimator_2, ... X_train=X_train, ... y_train=y_train, ... X_test=X_test, ... y_test=y_test ... ) >>> report = ComparisonReport([estimator_report_1, estimator_report_2]) >>> report.cache_predictions() >>> report._cache {...}
- clear_cache()[source]#
Clear the cache.
Examples
>>> from sklearn.datasets import make_classification >>> from sklearn.linear_model import LogisticRegression >>> from sklearn.model_selection import train_test_split >>> from skore import ComparisonReport >>> X, y = make_classification(random_state=42) >>> X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42) >>> estimator_1 = LogisticRegression() >>> estimator_report_1 = EstimatorReport( ... estimator_1, ... X_train=X_train, ... y_train=y_train, ... X_test=X_test, ... y_test=y_test ... ) >>> estimator_2 = LogisticRegression(C=2) # Different regularization >>> estimator_report_2 = EstimatorReport( ... estimator_2, ... X_train=X_train, ... y_train=y_train, ... X_test=X_test, ... y_test=y_test ... ) >>> report = ComparisonReport([estimator_report_1, estimator_report_2]) >>> report.cache_predictions() >>> report.clear_cache() >>> report._cache {}
- get_predictions(*, data_source, response_method, X=None, pos_label=None)[source]#
Get estimator’s predictions.
This method has the advantage to reload from the cache if the predictions were already computed in a previous call.
- Parameters:
- data_source{“test”, “train”, “X_y”}, default=”test”
The data source to use.
“test” : use the test set provided when creating the report.
“train” : use the train set provided when creating the report.
“X_y” : use the provided
Xandyto compute the metric.
- response_method{“predict”, “predict_proba”, “decision_function”}
The response method to use.
- Xarray-like of shape (n_samples, n_features), optional
When
data_sourceis “X_y”, the input features on which to compute the response method.- pos_labelint, float, bool or str, default=None
The positive class when it comes to binary classification. When
response_method="predict_proba", it will select the column corresponding to the positive class. Whenresponse_method="decision_function", it will negate the decision function ifpos_labelis different fromestimator.classes_[1].
- Returns:
- list of np.ndarray of shape (n_samples,) or (n_samples, n_classes)
The predictions for each cross-validation split.
- Raises:
- ValueError
If the data source is invalid.
Examples
>>> from sklearn.datasets import make_classification >>> from sklearn.model_selection import train_test_split >>> from sklearn.linear_model import LogisticRegression >>> from skore import ComparisonReport, EstimatorReport >>> X, y = make_classification(random_state=42) >>> X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42) >>> estimator_1 = LogisticRegression() >>> estimator_report_1 = EstimatorReport( ... estimator_1, ... X_train=X_train, ... y_train=y_train, ... X_test=X_test, ... y_test=y_test ... ) >>> estimator_2 = LogisticRegression(C=2) # Different regularization >>> estimator_report_2 = EstimatorReport( ... estimator_2, ... X_train=X_train, ... y_train=y_train, ... X_test=X_test, ... y_test=y_test ... ) >>> report = ComparisonReport([estimator_report_1, estimator_report_2]) >>> report.cache_predictions() >>> predictions = report.get_predictions( ... data_source="test", response_method="predict" ... ) >>> print([split_predictions.shape for split_predictions in predictions]) [(25,), (25,)]
Gallery examples#
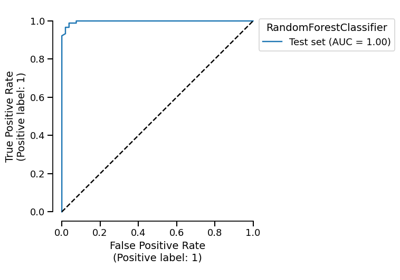
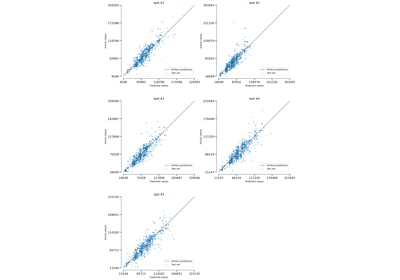
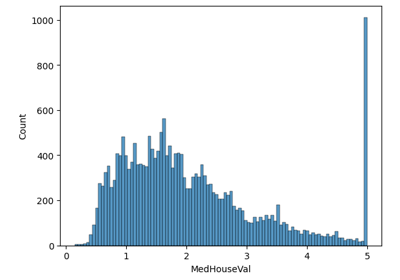
EstimatorReport: Inspecting your models with the feature importance